
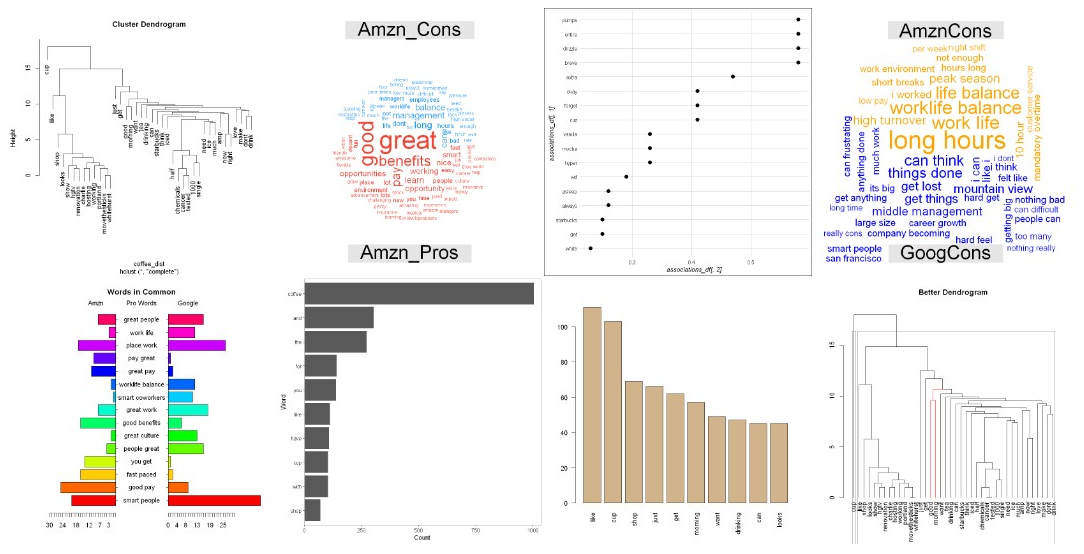
Mining Text
Topics: natural language processing, sentiment analysis, and topic modeling. Build a corpus of texts (documents or any tweet, email, comment, publication, status, etc.). Download data using APIs. Populate a database. Explore the statistics. Filter and extract regular expressions. Visualize words, frequencies, ngrams. Assess sentiment, draw conclusions, and provide advice.
Code: R / Tool: Jupyter
Consult the case in a new tab.
Text mining and web scraping with Python
- Chapter 9 from Managing Your Biological Data with Python has cases about finding patterns, regex, and pulling excerpts from texts and webpages with the
re, urllib2modules. - Chapter 11 from Automate the Boring Stuff with Python has examples on web scraping with the
webbrowser, requests, bs4, seleniummodules (bs4for Beautiful Soup). scrapyis another module for web scraping.- For serious Natural Language Processing, we should consider the NLTK (Natural Language ToolKit).
Mixing text mining and art. Extracting punctuation from classic novels and turning the resulting string into a spiral. For other pieces, go check out the website: C82.

